Mit einem sogenannten ELK-Stack können Server-Logfiles zentral gesammelt, analysiert und die Analyseergebnisse graphisch repräsentiert werden. Die Analyse kann z.B. Antworten auf folgende Fragen liefern:
- Wie viele Zugriffsversuche auf meine Server wurden unternommen?
- Wie viele HTTP-Requests pro Minute verarbeitet mein Webserver?
- Wirken die Anti-Spam-Maßnahmen?
Da die Logfiles zentral gespeichert werden, ist die Analyse über viele Server hinweg sehr angenehm und einfach machbar. In diesem Beitrag soll es um die Einrichtung eines solchen ELK-Stacks gehen. Verwendet werden die Elasticsearch-Produkte Filebeat, Logstash, Elasticsearch und Kibana.
- Filebeat: Läuft auf den zu überwachenden Servern und übermittelt die Log-Einträge an den zentralen ELK-Server
- Logstash: Parst die Log-Einträge und trägt sie in die Elasticsearch-Datenbank ein
- Elasticsearch: Ist die Suchmaschine, mit der sich der Datenbestand durchsuchen und analysieren lässt
- Kibana: Ist ein Web-Frontend für Elasticsearch und kann Analyseergebnisse graphisch darstellen
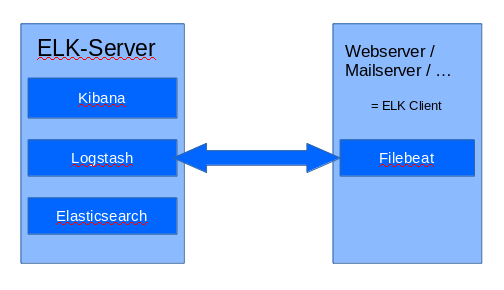
In meinem Setup gibt es einen zentralen ELK-Server, der selbst keine Logs für die Log-Datenbank liefert und nur für den ELK-Stack bereitsteht. Webserver, Mailserver und andere Server („ELK-Clients“) senden ihre Log-Daten via Filebeat an den ELK-Server. Alle Server (sowohl ELK-Server als auch ELK-Clients) laufen unter Ubuntu Server 14.04 LTS.
In dieser Anleitung wird fast permanent mit dem root-User gearbeitet. Meldet euch also zuerst als root an eurem künftigen ELK-Server an:
Java installieren
Elasticsearch, Logstash und Kibana benötigen Java, um zu funktionieren. In meinem Fall hat sich OpenJDK 7 als geeignet erwiesen:
apt install openjdk-7-jre-headless
(Daher auch der dedizierte ELK-Server in meinem Setup – Java + der Stack sind durchaus RAM-hungrig. Um auf meinen virtuellen Server nicht teuer weiteren RAM buchen zu müssen, betreibe ich den ELK-Server in einer KVM-Maschine auf meinem NAS Zuhause)
Elasticsearch installieren
Als erste Komponente auf dem ELK-Server wird Elasticsearch installiert. Eine aktuelle Version kann man aus dem Debian-Repository des Entwicklerunternehmens beziehen. Dazu muss zunächst der PGP Public Key für das Repo heruntergeladen werden:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Nun wird das ES Repository zu den Paketquellen hinzugefügt:
echo "deb http://packages.elastic.co/elasticsearch/2.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-2.x.list
… und Elasticsearch installiert:
apt update apt install elasticsearch
Elasticsearch Konfiguration
Die Konfiguration von Elasticsearch ist schnell erledigt. In der Konfigurationsdatei /etc/elasticsearch/elasticsearch.yml wird im „network“-Abschnitt vor der Zeile
network.host: 192.168.0.1
das Kommentarzeichen (#) entfernt und statt der IP-Adresse „localhost“ gesetzt:
network.host: localhost
Damit erreichen wir, dass die Elasticsearch-API nur lokal auf dem Rechner verfügbar ist und nicht von außen auf die Log-Daten zugegriffen werden kann. Dann wird Elasticsearch zum Autostart des Systems hinzugefügt und neu gestartet:
update-rc.d elasticsearch defaults 95 10 service elasticsearch restart
Kibana installieren
Auch für Kibana gibt es ein Repository, welches zum System hinzugefügt wird:
echo "deb http://packages.elastic.co/kibana/4.4/debian stable main" | sudo tee -a /etc/apt/sources.list.d/kibana-4.4.x.list
Installiert wird wie immer mit:
apt update apt install kibana
Kibana konfigurieren
Auch in der Kibana-Konfiguration unter /opt/kibana/config/kibana.yml muss nicht viel geändert werden. Kibana wird über einen Reverse Proxy (inkl. Zugriffsschutz) bereitgestellt und soll daher nicht direkt und ungeschützt erreichbar sein. Die Zeile
server.host: "0.0.0.0"
wird „einkommentiert“ (# entfernen) und das „0.0.0.0“ durch „localhost“ ersetzt:
server.host: "localhost"
Der Kibana-Dienst wird im Autostart verankert und gestartet:
update-rc.d kibana defaults 96 9 service kibana start
Nginx Reverse Proxy für Kibana
Als Reverse Proxy für Kibana wird Nginx genutzt. Ich gehe davon aus, dass ihr mit Nginx vertraut seid, und gebe euch daher nur kurz eine Beispielkonfiguration für den Proxy an:
server {
server_name kibana.mein-elk-server.tld;
listen 80;
listen [::]:80;
listen 443 ssl;
listen [::]:443 ssl;
ssl_certificate /etc/myssl/fullchain.pem;
ssl_certificate_key /etc/myssl/privkey.pem;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/kibana.users;
location / {
access_log off;
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Die .htpasswd-Datei zur Absicherungs des Webinterfaces mit einem Benutzernamen und einem Passwort wurde via
sudo htpasswd -c /etc/nginx/kibana.users username
erzeugt. (Dafür müssen die apache2-utils installiert sein).
Prinzipiell kann man natürlich auch Apache als HTTP-Reverse-Proxy für Kibana nutzen. Nach erfolgter Webserver-Konfiguration sollte Kibana unter dem jeweiligen Domain-Namen (hier kibana.mein-elk-server.tld) erreichbar sein. Um das Webinterface kümmern wir uns jedoch erst später wieder.
(Siehe auch: Apache Reverse Proxy)
Logstash installieren
Logstash installieren:
echo 'deb http://packages.elastic.co/logstash/2.2/debian stable main' | sudo tee /etc/apt/sources.list.d/logstash-2.2.x.list apt update apt install logstash
Für Authentifizierung und Verschlüsselung der Daten zwischen den ELK-Clients und Logstash müssen x509-Zertifikate erzeugt werden:
mkdir -p /etc/pki/tls/certs mkdir /etc/pki/tls/private cd /etc/pki/tls openssl req -subj '/CN=mein-elk-server.tld/' -x509 -days 3650 -batch -nodes -newkey rsa:4096 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
Wobei „mein-elk-server.tld“ natürlich angepasst werden muss. Der Domain-Name zeigt auf die IP-Adresse des ELK-Servers.
Logstash konfigurieren
Zur Konfiguration von Logstash wird in das Verzeichnis /etc/logstash/conf.d gewechselt. Dort werden im folgenden 3 Dateien angelegt. Die erste Datei soll „02-filebeat-input.conf“ heißen und legt fest, auf welchen Port Logstash lauschen soll und welcke PKI genutzt werden soll:
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
}
}
Die zweite Datei „10-syslog-filter.conf“ enthält einen Filter, der für das parsing von Syslog-Einträgen notwendig ist:
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
Zuletzt wird die Datei „30-elasticsearch-output.conf“ erstellt, sodass Logstash angewiesen wird, die Log-Daten nach dem Parsing zu Elasticsearch zu übermitteln:
output {
elasticsearch {
hosts => ["localhost:9200"]
sniffing => true
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
Wenn ihr neben der 10-syslog-filter.conf-Filterdatei weitere Filter anlegen wollt, achtet darauf, dass sich der Filter zwischen input und output befindet. In diesem Fall müssen die Dateinamen mit Zahlen zwischen 03 und 29 beginnen, z.B. 11-meinfilter.conf
Die Logstash-Konfiguration kann mit
service logstash configtest
getestet werden. Wenn die Ausgabe „Configuration OK“ erscheint, kann Logstash neu gestartet werden:
service logstash restart
Logstash wird außerdem zum Autostart hinzugefügt:
update-rc.d logstash defaults 96 9
Kibana Dashboard für Filebeat erweitern
Für eine einfachere Bedienung von Kibana werden ein paar Beispiel-Dashboards installiert.
cd ~ curl -L -O https://download.elastic.co/beats/dashboards/beats-dashboards-1.1.0.zip
Entpacken mit unzip: (apt install unzip)
unzip beats-dashboards-1.1.0.zip
Dashboards laden:
cd beats-dashboards-1.1.0/ ./load.sh
Damit Kibana mit Filebeat zusammenarbeitet, wird noch das Filebeat Index Template installiert:
cd ~ curl -O https://gist.githubusercontent.com/thisismitch/3429023e8438cc25b86c/raw/d8c479e2a1adcea8b1fe86570e42abab0f10f364/filebeat-index-template.json
Template laden:
curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@filebeat-index-template.json
Wenn dabei
{
"acknowledged" : true
}
zurückgegeben wird, hat der Import funktioniert.
Filebeat auf zu überwachenden Servern einrichten
Damit ein Server (ELK-Client) seine Log-Daten an den ELK-Server übermitteln kann, muss er über das vorher angelegte x509-Zertifikat verfügen. Dazu wird das Zertifikat zuerst vom ELK-Server auf den lokalen Rechner kopiert. (das folgende Kommando auf dem lokalen Rechner ausführen)
scp root@mein-elk-server.tld:/etc/pki/tls/certs/logstash-forwarder.crt /tmp
(Jetzt auf dem zu überwachenden Server einloggen) Nun wird auf dem ELK-Client die passende Verzeichnisstruktur erzeugt:
mkdir -p /etc/pki/tls/certs
und logstash-forwarder.crt dorthin kopiert: (folgendes Kommando wieder auf dem lokalen Rechner ausführen!)
scp /tmp/logstash-forwarder.crt root@mein-elk-client:/etc/pki/tls/certs/logstash-forwarder.crt
Wieder zurück auf dem ELK-Client wird das Filebeat-Repository hinzugefügt, der passende PGP-Schlüssel heruntergeladen und Filebeat installiert:
echo "deb https://packages.elastic.co/beats/apt stable main" | sudo tee -a /etc/apt/sources.list.d/beats.list wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - apt update apt install filebeat
Nach der Installation wird Filebeat über die Konfigurationsdatei /etc/filebeat/filebeat.yml konfiguriert. Die bereits vorhandene Beispielkonfiguration ist etwas unübersichtlich, daher wird sie als Backup zur Seite geschoben …
cd /etc/filebeat mv filebeat.yml filebeat.yml.bak
… und durch eine neue Konfiguration ersetzt:
nano filebeat.yml
In der Konfigurationsdatei wird beschrieben, welche Log-Dateien an den ELK-Server übermittelt werden sollen und um welchen Log-Typ es sich handelt. Meine Konfiguration sieht beispielsweise so aus:
filebeat: prospectors: - document_type: nginx input_type: log paths: - /var/log/nginx/*.log - document_type: auth input_type: log paths: - /var/log/auth.log registry_file: /var/lib/filebeat/registry output: logstash: hosts: ["mein-elk-server.tld:5044"] bulk_max_size: 1024 tls: certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"] shipper: logging: files: rotateeverybytes: 10485760 # = 10MB
Filebeat nimmt es ziemlich genau mit der Konfigurationsdatei: Auf jede Einrückung muss geachtet werden! Ich habe euch einen Block in der Konfiguration blau markiert. Ein solcher Block sorgt dafür, dass die genannte Log-Datei an den ELK-Server übermittelt wird. Ihr könnt nach dem Muster oben beliebige weitere Blöcke hinzufügen.
Damit die Konfiguration übernommen wird, wird Filebeat neu gestartet und zum Autostart hinzugefügt:
service filebeat restart update-rc.d filebeat defaults 95 10
Das war’s auch schon! Unmittelbar nach dem Start sendet Filebeat Log-Daten zum ELK-Server, wo sie in die Log-Datenbank aufgenommen werden.
Der letzte Schliff …
Eine Kleinigkeit noch: In Kibana wird auf der linken Seite „filebeat-*“ aus der Liste gewählt und dann auf den grünen Stern geklickt, damit „filebeat-*“ als Default Index gesetzt wird. In den Reitern „Discover“ und „Visualize“ könnt ihr euch jetzt austoben und verschiedenste Suchanfragen eingeben. Abgespeicherte Visualisierungen können zum Dashboard hinzugefügt werden. Alles weitere probiert ihr am besten einfach aus… ;)
RAM-Verbrauch drosseln
Logstash und Kibana brauchen standardmäßig sehr viel RAM. Wie ihr den Verbrauch drosseln und damit Abstürze der Komponenten verhindert, könnt ihr hier nachlesen: Logstash und Elasticsearch RAM-Verbrauch reduzieren

Danke für den ausführlichen Post. Das will ich auch demnächst mal ausprobieren.
Hi Thomas,
danke für den Artikel…
zwei Fragen:
– Die Logs, die via Filebeat an den ELK-Server gehen, werden die dort auch nochmals persistiert?
– Was hast Du für ein NAS, dass Du dort ne KVM installieren kannst…?
https://legacy.thomas-leister.de/ueber-mich-und-blog/
Hi Jens,
ja, die Daten bleiben auf dem ELK-Server erhalten. Ich kann dir nur aktuell noch keine Angaben dazu machen, wie lange (bzw wie man das umstellt) weil das Thema für mich selbst noch neu ist. Mein NAS ist ein Eigenbau, der mit Ubuntu Server 14.04 LTS läuft.
LG Thomas
Hi Thomas,
hast Du einen ungefähren Anhaltspunkt, wieviel RAM der ELK-Server sich einverleibt? Habe leider aktuell keine Möglichkeit, auf meinem QNAP NAS eine VM zu installieren… Und da bleibt mir dann nur ein vServer im Netz…
https://legacy.thomas-leister.de/ueber-mich-und-blog/
Gestern habe ich einfach mal versucht, der Maschine nur 1 GB RAM zuzuteilen… den (und den Auslagerungsspeicher) hat ES fast ganz voll geschrieben. Heute morgen habe ich nochmal 500 MB dazugegeben, aber auch die sind schon fast wieder aufgefressen. Das Ding ist echt hungrig… oder es ist Absicht, dass es sich nimmt, was es bekommen kann. Ich weiß es nicht. Würde dir zu 2 GB aufwärts raten (wenn du sonst nichts auf dem vServer laufen lässt)
LG Thomas
Ok, dann muss ich mir wohl überlegen, auf den XL-Server bei Servercow zu wechseln… :(
Hallo Thomas,
auch von mir ein Dankeschön für die gute Anleitung.
Leider ist mir in dem Unterkapitel „Filebeat auf zu überwachenden Servern einrichten“ noch ein wenig unklar, was auf welchem Server eingerichtet werden muss. Vielleicht bin ich einfach nur zu verwirrt von deiner Namensgebung….
Du sagst zum einen immer ELK-Client, ELK-Server und zusätzlich noch lokalen Rechner. Was von dem allem meinst du jetzt?
Meine Situation ist, dass ich halt einen „ELK-Server“ mit Elasticsearch, Logstash, Filebeat und Kibana habe und dann einen stink-normalen WebServer, auf diesen ich zugreifen und sozusagen Filebeat einrichten möchte, damit ich mit Kibana zugriff habe und auswerten kann…
Vielleicht war es auch einfach nur ein zu langer Tag gewesen, aber ich stehe gerade ein wenig auf dem Schlauch, was ich wo einrichten muss, damit dies so funktioniert, wie ich mir das vorstelle.
Ich danke dir trotzdem schon mal für alles.
Liebe Grüße
Adrian
https://legacy.thomas-leister.de/ueber-mich-und-blog/
Hi, ja, meine Namensgebung ist vllt nicht gleich klar. Die Anleitung geht davon aus, dass 3 Rechner im Spiel sind:
1) Der Rechner, vor dem du gerade sitzt. „Lokaler Rechner“. Der ist in der Anleitung nur erwähnt, weil ein ein SSH Public Key über den umweg ausgetauscht wird. Man müsste sonst eine SSH-Verbindung direkt zwischen den Servern herstellen und das finde ich nicht gut.
2) Dein ELK-Server für den ELK-Stack (Elastic Search, Logstasg, Kibana)
3) Ein dritter Server, dessen Logs zum ELK-Server geschickt und dort analysiert werden sollen. Auf diesem Server läuft z.B. dein Webserver oder dein Mailserver. Auf diesem zu überwachenden Server richtest du Filebeat ein.
Vielleicht kann ich später noch eine kleine Grafik basteln, damit die Aufteilung schneller klar wird.
Update: Ich habe zu Beginn des Beitrags eine kleine Grafik eingefügt. Vielleicht wird es dadurch verständlicher.
LG Thomas
Hallo Thomas
Gute Anleitung, Danke.
Eine frage habe ich noch, braucht es Filetbeat zur Übermittlung der Logdateien oder kann dies wie bei Graylog2 das System eigene rsyslog verwenden?
Gruss
Simi